bruno78
Membres
-
Inscription
-
Dernière visite
Tout ce qui a été posté par bruno78
-
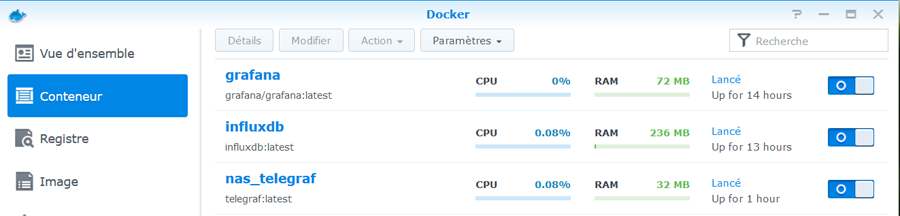
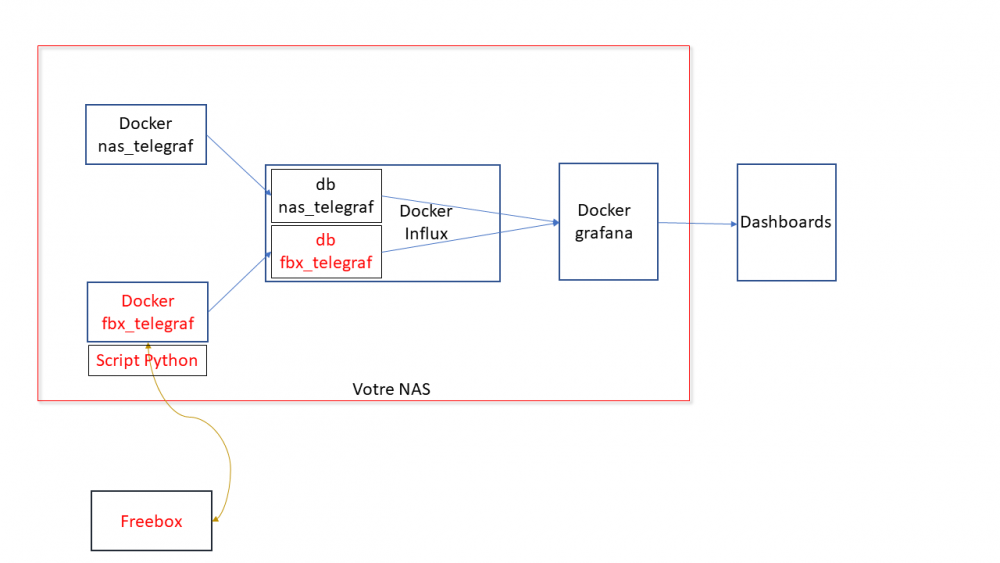
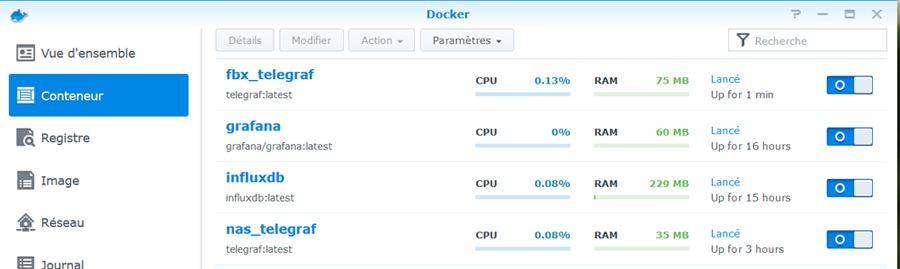
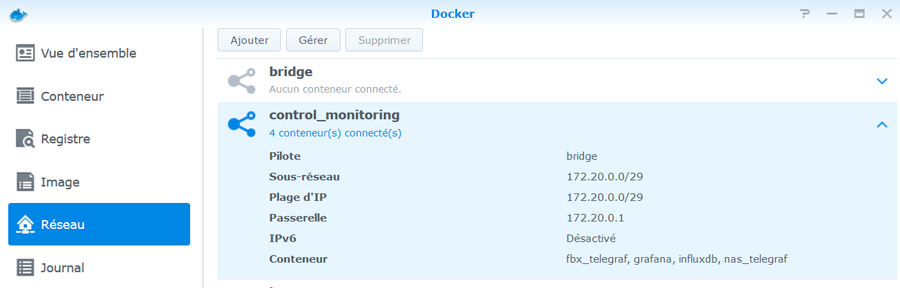
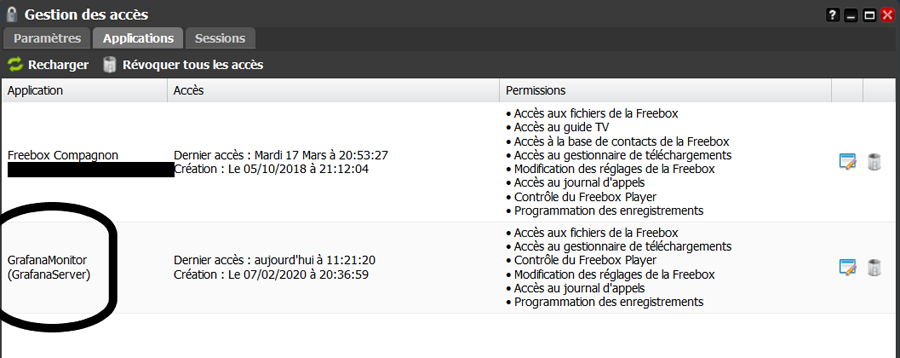
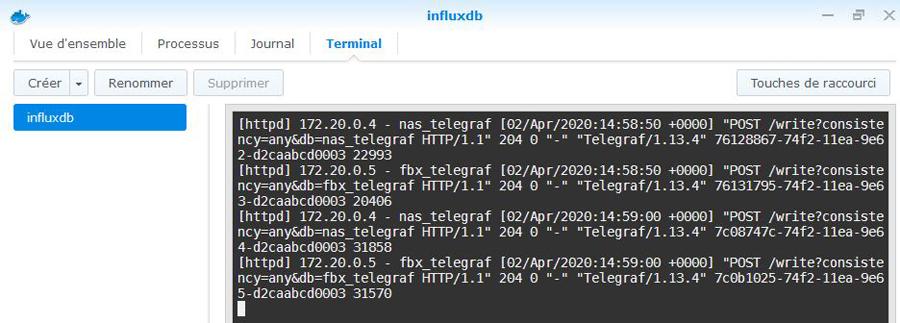
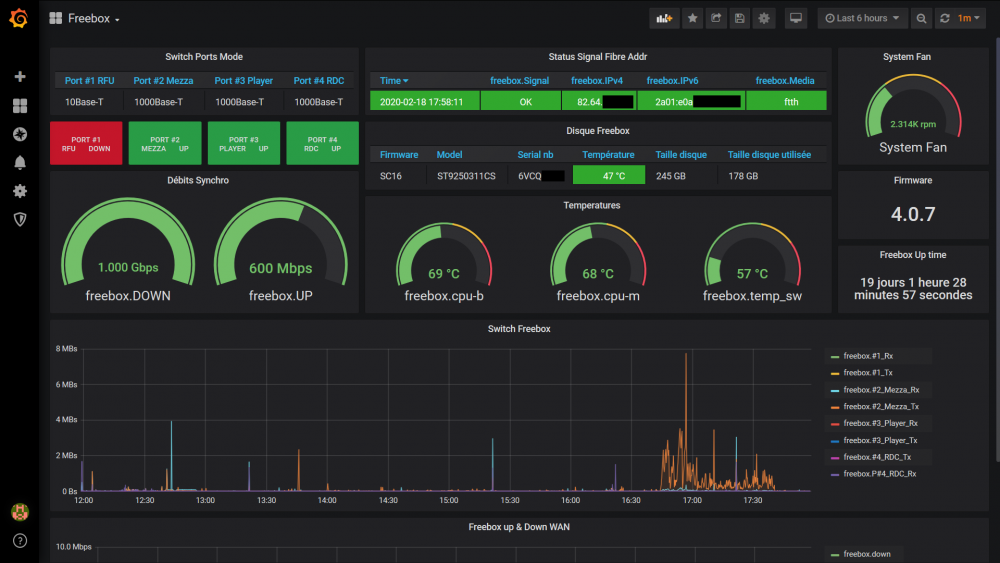
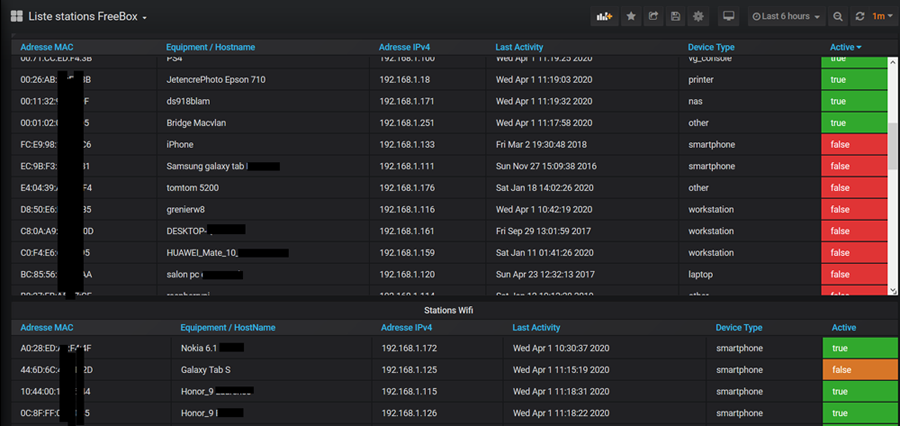
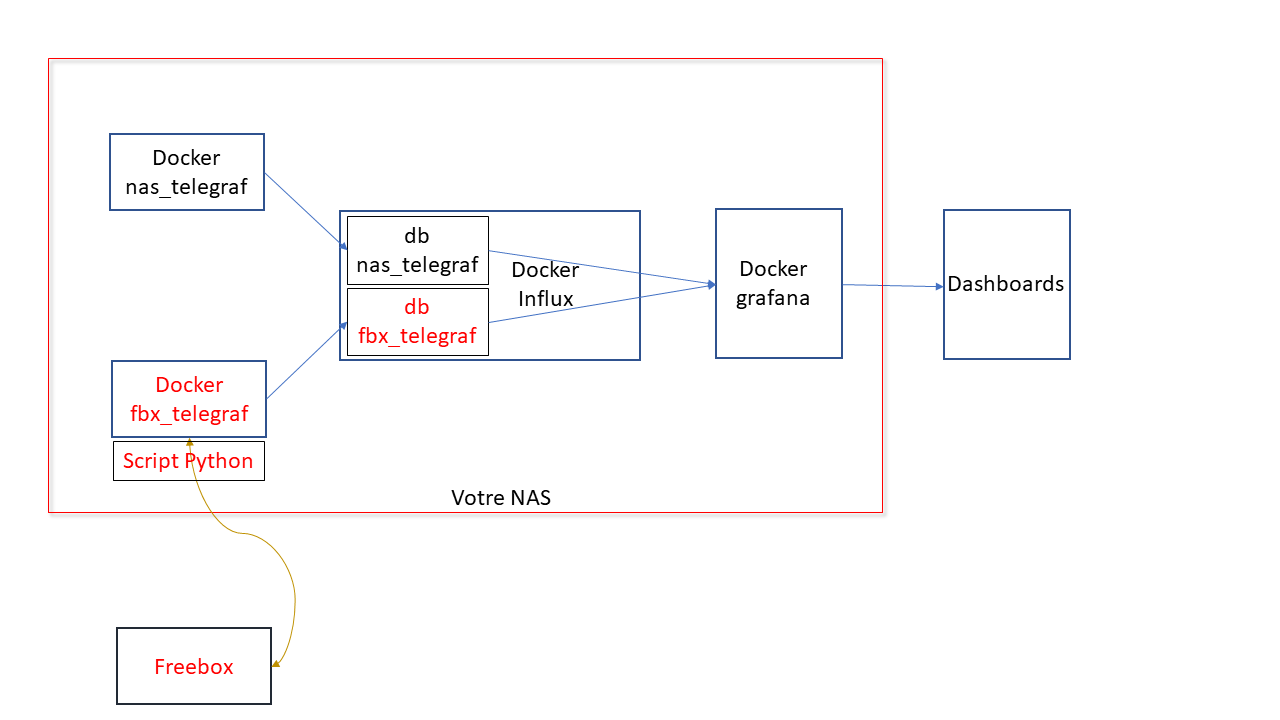
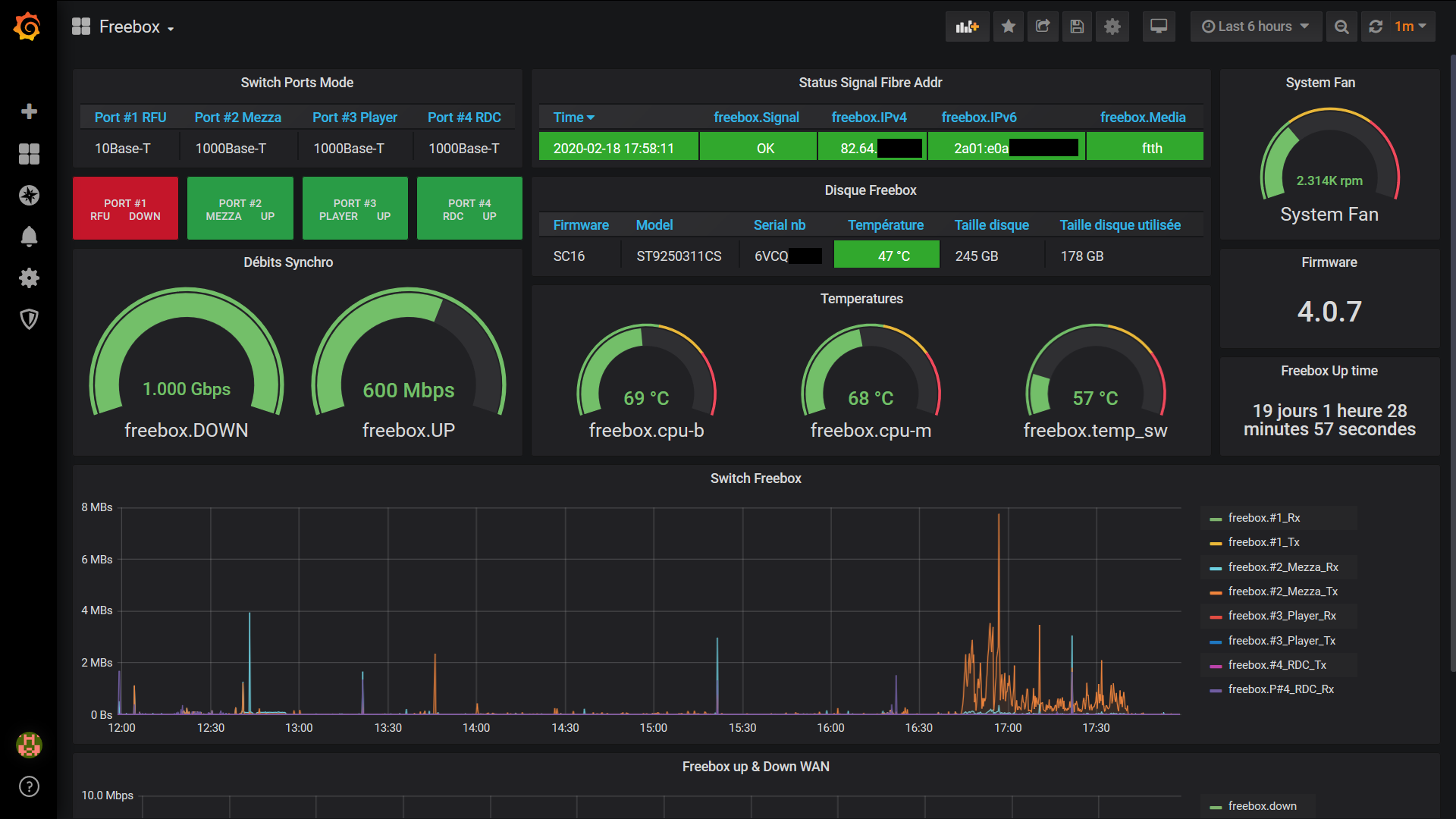
 Il s'agit ici de présenter un tuto pour monitorer sa Freebox, avec les outils telegraf / influxdb / grafana, en complément du [TUTO] Monitoring NAS et Réseau qui reste la référence. En conséquence, je suppose déjà opérationnelle chez vous une chaine complète telegraf / influxdb / grafana pour la supervision de votre NAS Il faudra bien entendu faire les adaptations spécifiques à votre environnement. Principe : Le docker telegraf va utiliser un script python pour récupérer les infos de la Freebox. Limites : je n'ai pu valider cette méthode que sur ma Freebox, et donc pour les autres modèles et/ou configuration ... ? Freebox Révolution au dernier Firmware (4.0.7) à ce jour. Accès réseau fibre ftth (et donc pas testé les compteurs xDSL) Chaine existante (hypothèse) : je suppose donc que vous avez une chaine telegraf / influxdb / grafana opérationnelle pour votre NAS, en docker mode bridge. Ajout Freebox : On va rajouter un second docker telegraf, qui portera le script Python. Ce docker telegraf dédié Freebox va transmettre ses données vers une seconde database que l'on va créer dans le docker Influx Sur grafana, on créera une nouvelle source de données (la nouvelle database d'influx) qui nous permettra d'afficher les données Freebox. Voir schéma de principe ci-dessous : Configuration des dockers existants : subnet: 172.20.0.0/29 gateway: 172.20.0.1 ip_range: 172.20.0.0/29 Adressage existant grafana d2:ca:ab:cd:00:02 172.20.0.2 influxdb d2:ca:ab:cd:00:03 172.20.0.3 nas_telegraf d2:ca:ab:cd:00:04 172.20.0.4 Création du nouveau docker : fbx_telegraf Adressage sur le réseau bridge : fbx_telegraf d2:ca:ab:cd:00:05 172.20.0.5 Déclaration du service fbx_telegraf dans le docker-compose.yaml (extrait): EDIT du 02/septembre 2020 : la dernière branche de developpement du docker telegraf, 1.15.x, semble poser problème avec Python. Il faut donc se limiter au max à la version 1.14.5. L'image à charger sera donc telegraf:1.14.5 au lieu de telegraf:latest EDIT du 08/septembre 2020 : installation résolue pour python sur la branche telegraf 1.15.x (i.e. tag : latest). Voir détails plus bas. services: fbx_telegraf: image: telegraf:latest container_name: fbx_telegraf hostname: fbx_telegraf mac_address: d2:ca:ab:cd:00:05 networks: monitoring: ipv4_address: 172.20.0.5 environment: - PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/bin:/sbin:/usr/local:/usr/src - TZ=CET mem_limit: 75M volumes: - "/volume1/docker/monitoring/fbx_telegraf/telegraf.conf:/etc/telegraf/telegraf.conf:ro" # pour le fichier de commande python d'acces a la freebox, # pour le fichier de commande python, # pour le fichier get-pip.py (install module pip puis requests) - "/volume1/docker/monitoring/fbx_telegraf/py:/usr/local/py" # pour le fichier log si on le met en place - "/volume1/docker/monitoring/fbx_telegraf/log:/usr/local/log" ports: - 9125:8125/udp - 9092:8092/udp - 9094:8094 restart: unless-stopped On notera la création et le mapping de 2 répertoires pour le docker fbx_telegraf: un répertoire pour le fichier Python et le fichier d'installation de l'utilitaire python "pip" : /usr/local/py un répertoire pour d’éventuels logs : /usr/local/log Création et démarrage du docker fbx_telegraf: docker-compose pull fbx_telegraf docker-compose up -d fbx_telegraf Via un accès ssh sur le NAS : mise à jour du docker fbx_telegraf docker exec -it fbx_telegraf apt update docker exec -it fbx_telegraf apt upgrade docker exec -it fbx_telegraf apt install -y software-properties-common Installation de python3 dans le docker telegraf télécharger get-pip.py (https://bootstrap.pypa.io/get-pip.py) dans le répertoire /usr/local/py installation des modules pip et requests docker exec -it fbx_telegraf wget https://bootstrap.pypa.io/get-pip.py docker exec -it fbx_telegraf python3 get-pip.py --prefix=/usr/local docker exec -it fbx_telegraf python3 -m pip install requests docker exec -it fbx_telegraf pip install unidecode EDIT du 08/septembre 2020 : installation Python sur la branche telegraf:1.5.x (i.e. tag latest) Au lieu des 7 commandes ci-dessus, on procèdera de la sorte : docker exec -it fbx_telegraf apt update docker exec -it fbx_telegraf apt upgrade docker exec -it fbx_telegraf dpkg --configure -a docker exec -it fbx_telegraf apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common docker exec -it fbx_telegraf wget https://bootstrap.pypa.io/get-pip.py docker exec -it fbx_telegraf apt-get install python3-distutils docker exec -it fbx_telegraf python3 get-pip.py --prefix=/usr/local docker exec -it fbx_telegraf python3 -m pip install requests docker exec -it fbx_telegraf pip install unidecode Il se peut que vous ayez une erreur du type : E: dpkg was interrupted, you must manually run 'dpkg --configure -a' to correct the problem Dans ce cas, .... suivre à la lettre la consigne et lancer donc la commande # dpkg --configure -a . Puis poursuivre normalement Script Python : On place le script Python fbx_telegraf_059.py dans le répertoire /usr/local/py (ce script a été mis à jour pour mes propres besoins. N’hésitez pas à le reprendre, en particulier en fonction de l'API Freebox si il vous manque des éléments) EDIT du 27/04/2021 : mise à jour du fichier python en version ed061. version basée sur l'API V8 de FreeboxOs compatibilité avec Freebox POP je conseille de repartir d'une database InfluxDB vierge cf message en page 9 pour plus de détails c'est par ici : https://github.com/bruno78310/Freebox-Revolution-Monitoring.git Modification du fichier de configuration telegraf : 1) Dans la section "Input Plugin" : ############################################################################### # INPUT PLUGINS # ############################################################################### ############################################################################### # INPUT PLUGINS FREEBOX # ############################################################################### # Read metrics from one or more commands that can output to stdout [[inputs.exec]] ## Commands array # commands = [ "python3 /usr/local/py/freebox_059.py -SPHDIWX" ] ## Timeout for each command to complete. timeout = "5s" ## Data format to consume. ## Each data format has it's own unique set of configuration options, read ## more about them here: ## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md # data_format = "graphite" data_format = "influx" A noter : le script python "freebox_059.py" est lancé avec un certain nombre d'options, chacune correspondant à un groupe de données récupérées. Si on n'a pas besoin de toutes ces données, selon les besoins, il est tout à fait possible de supprimer les options que l'on ne souhaite pas grapher. freebox_059.py -SPHDIWX : S : état du switch 4 ports X : liste les hosts connectés P : état des ports du switch H : system status D : status disque interne I : status des interfaces LAN W : status du Wifi 4 : status aggregation xdsl / 4g 2) modification de la base influxdb cible, section "Output Plugins" : On va envoyer nos données vers une base de données du nom de fbx_database, user fbx_databse, password fbx_database De plus, on va créer nous même cette database => skip_database_creation = true ############################################################################### # OUTPUT PLUGINS # ############################################################################### # Configuration for sending metrics to InfluxDB [[outputs.influxdb]] ## The full HTTP or UDP URL for your InfluxDB instance. ## ## Multiple URLs can be specified for a single cluster, only ONE of the ## urls will be written to each interval. # urls = ["unix:///var/run/influxdb.sock"] # urls = ["udp://127.0.0.1:8089"] urls = ["http://influxdb:8086"] ## The target database for metrics; will be created as needed. ## For UDP url endpoint database needs to be configured on server side. database = "fbx_telegraf" ## The value of this tag will be used to determine the database. If this ## tag is not set the 'database' option is used as the default. database_tag = "" ## If true, the database tag will not be added to the metric. # exclude_database_tag = false ## If true, no CREATE DATABASE queries will be sent. Set to true when using ## Telegraf with a user without permissions to create databases or when the ## database already exists. skip_database_creation = true ## Name of existing retention policy to write to. Empty string writes to ## the default retention policy. Only takes effect when using HTTP. retention_policy = "" ## Write consistency (clusters only), can be: "any", "one", "quorum", "all". ## Only takes effect when using HTTP. write_consistency = "any" ## Timeout for HTTP messages. timeout = "30s" ## HTTP Basic Auth username = "fbx_telegraf" password = "fbx_telegraf" ## HTTP User-Agent # user_agent = "telegraf" On redémarre le docker fbx_telegraf pour prise en compte Création de la database fbx_telegraf sur influxdb Se connecter en console sur le docker influxdb, puis créer la database : root@influxdb:/# influx -username admin -password admin Connected to http://localhost:8086 version 1.7.9 InfluxDB shell version: 1.7.9 > show databases name: databases name ---- _internal nas_telegraf > create database fbx_telegraf > use fbx_telegraf Using database fbx_telegraf > create user fbx_telegraf with password 'fbx_telegraf' > grant all on fbx_telegraf to fbx_telegraf > > show databases name: databases name ---- _internal nas_telegraf fbx_telegraf > show users user admin ---- ----- admin true nas_telegraf false fbx_telegraf false > On redémarre le docker influxdb pour prise en compte. Autorisation de l'application sur le Freebox. il faut autoriser l'application sur la Freebox. Pour cela se placer dans une console fbx_telegraf et aller dans le dossier /usr/local/py root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -h usage: freebox_050.py [-h] [-s] [-r] [-n app_name] [-i app_id] [-d device_name] [-f format] [-e endpoint] [-S] [-P] [-H] [-D] [-L] [-W] [-I] [-X] optional arguments: -h, --help show this help message and exit -s, --register-status Get register status -r, --register Register app with Freebox API -n app_name, --appname app_name Register with app_name -i app_id, --appid app_id Register with app_id -d device_name, --devicename device_name Register with device_name -f format, --format format Specify output format between graphite and influxdb -e endpoint, --endpoint endpoint Specify endpoint name or address -S, --status-switch Get and show switch status -P, --status-ports Get and show switch ports stats -H, --status-sys Get and show system status -D, --internal-disk-usage Get and show internal disk usage -L, --lan-config Get and show LAN config -W, --wifi-usage Get and show wifi usage -I, --lan-interfaces Get and show lan interfaces -X, --interfaces-hosts Get and show interfaces hosts On va demander d'enregistrer notre application sur la Freebox: root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -r => il faut valider sur l'ecran LCD de la Freebox. => le nom de l'application codée dans le fichier fbx_telegraf_059.py est : grafanamonitor. => controler sur la Freebox que l'application a bien été acceptée : Paramètres / Gestion des Accès / Applications on peut aussi vérifier sur la console fbx_telegraf : root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -s Status: auth already done root@fbx_telegraf:/usr/local/py# root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -r Already registered, exiting root@fbx_telegraf:/usr/local/py# Vous trouverez alors un fichiers .credentials dans le répertoire /usr/local/py . A partir de là, fbx_telegraf est en mesure de collecter les données sur la Freebox, et de les envoyer sur la base de données fbx_telegraf du docker influxdb. on peut contrôler à la main que les valeurs sont bien accessibles, par exemple : root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -H | grep System freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL sys_uptime_val=2787529 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL uptime="32 jours 6 heures 18 minutes 49 secondes" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL firmware_version="4.2.5" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL board_name="fbxgw2r" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL disk_status="active" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL user_main_storage="Disque dur" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_ext_telephony=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_speakers_jack=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL wifi_type="2d4_5g" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL pretty_name="Freebox Server (r2)" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL customer_hdd_slots=0 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL name="fbxgw-r2/full" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_speakers=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL internal_hdd_size=250 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_femtocell_exp=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_internal_hdd=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_dect=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Fan,tag3=NULL id="fan0_speed" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Fan,tag3=NULL name="Ventilateur 1" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Fan,tag3=NULL value=2436 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_hdd id="temp_hdd" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_hdd name="Disque dur" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_hdd value=36 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_sw id="temp_sw" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_sw name="Temperature Switch" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_sw value=48 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpum id="temp_cpum" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpum name="Temperature CPU M" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpum value=58 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpub id="temp_cpub" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpub name="Temperature CPU B" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpub value=53 root@fbx_telegraf:/usr/local/py# Dans la console du docker influxdb, on verifie que l'on recoit bien les données de nas_telegraf et fbx_telegraf Grafana : sur grafana, definir une nouvelle source de données : Name : InfluxDB-1 Freebox (example) URL : http://@NAS:8086 (comme pour le nas_telegraf,car c'est le même docker influxdb) Access : serveur Basic auth : yes Basic auth details : user : fbx_telegraf password : fbx_telegraf Database : fbx_telegraf User : fbx_telegraf password : fbx_telegraf http method : GET On valide (SAVE & TEST) et ce doit être OK. Il ne reste plus qu'à créer le ou les Dashboard souhaités ! => Ne pas oublier de préciser l'origine des données : InfluxDB-1 Freebox Pour ma part, j'ai réalisé: un Dashboard général (trafic, CPU, status des ports du switch, températures ....) un Dashboard listant les stations actives (globales et Wifi) Resterait à faire : l'API de la Freebox est accessible ici en http. Je n'ai pas réussi par manque de connaissances à passer en https je n'ai pas regardé du tout le cas d'un accès xDSL .... le script python s'appuie sur l'API V8 de la Freebox, et est donc compatible avec les Freebox Revolution et POP. La description de cet API peut se trouver ici : https://dev.freebox.fr/sdk/os/# Enfin, tous les paramètres disponibles n'ont pas forcement été implémentés dans le script. Mais les principaux sont là. SI il y avait un besoin particulier, faites le moi savoir. Freebox-1585840825569.json Liste stations FreeBox-1585840845020.json freebox_054.py freebox_058.py
Il s'agit ici de présenter un tuto pour monitorer sa Freebox, avec les outils telegraf / influxdb / grafana, en complément du [TUTO] Monitoring NAS et Réseau qui reste la référence. En conséquence, je suppose déjà opérationnelle chez vous une chaine complète telegraf / influxdb / grafana pour la supervision de votre NAS Il faudra bien entendu faire les adaptations spécifiques à votre environnement. Principe : Le docker telegraf va utiliser un script python pour récupérer les infos de la Freebox. Limites : je n'ai pu valider cette méthode que sur ma Freebox, et donc pour les autres modèles et/ou configuration ... ? Freebox Révolution au dernier Firmware (4.0.7) à ce jour. Accès réseau fibre ftth (et donc pas testé les compteurs xDSL) Chaine existante (hypothèse) : je suppose donc que vous avez une chaine telegraf / influxdb / grafana opérationnelle pour votre NAS, en docker mode bridge. Ajout Freebox : On va rajouter un second docker telegraf, qui portera le script Python. Ce docker telegraf dédié Freebox va transmettre ses données vers une seconde database que l'on va créer dans le docker Influx Sur grafana, on créera une nouvelle source de données (la nouvelle database d'influx) qui nous permettra d'afficher les données Freebox. Voir schéma de principe ci-dessous : Configuration des dockers existants : subnet: 172.20.0.0/29 gateway: 172.20.0.1 ip_range: 172.20.0.0/29 Adressage existant grafana d2:ca:ab:cd:00:02 172.20.0.2 influxdb d2:ca:ab:cd:00:03 172.20.0.3 nas_telegraf d2:ca:ab:cd:00:04 172.20.0.4 Création du nouveau docker : fbx_telegraf Adressage sur le réseau bridge : fbx_telegraf d2:ca:ab:cd:00:05 172.20.0.5 Déclaration du service fbx_telegraf dans le docker-compose.yaml (extrait): EDIT du 02/septembre 2020 : la dernière branche de developpement du docker telegraf, 1.15.x, semble poser problème avec Python. Il faut donc se limiter au max à la version 1.14.5. L'image à charger sera donc telegraf:1.14.5 au lieu de telegraf:latest EDIT du 08/septembre 2020 : installation résolue pour python sur la branche telegraf 1.15.x (i.e. tag : latest). Voir détails plus bas. services: fbx_telegraf: image: telegraf:latest container_name: fbx_telegraf hostname: fbx_telegraf mac_address: d2:ca:ab:cd:00:05 networks: monitoring: ipv4_address: 172.20.0.5 environment: - PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/bin:/sbin:/usr/local:/usr/src - TZ=CET mem_limit: 75M volumes: - "/volume1/docker/monitoring/fbx_telegraf/telegraf.conf:/etc/telegraf/telegraf.conf:ro" # pour le fichier de commande python d'acces a la freebox, # pour le fichier de commande python, # pour le fichier get-pip.py (install module pip puis requests) - "/volume1/docker/monitoring/fbx_telegraf/py:/usr/local/py" # pour le fichier log si on le met en place - "/volume1/docker/monitoring/fbx_telegraf/log:/usr/local/log" ports: - 9125:8125/udp - 9092:8092/udp - 9094:8094 restart: unless-stopped On notera la création et le mapping de 2 répertoires pour le docker fbx_telegraf: un répertoire pour le fichier Python et le fichier d'installation de l'utilitaire python "pip" : /usr/local/py un répertoire pour d’éventuels logs : /usr/local/log Création et démarrage du docker fbx_telegraf: docker-compose pull fbx_telegraf docker-compose up -d fbx_telegraf Via un accès ssh sur le NAS : mise à jour du docker fbx_telegraf docker exec -it fbx_telegraf apt update docker exec -it fbx_telegraf apt upgrade docker exec -it fbx_telegraf apt install -y software-properties-common Installation de python3 dans le docker telegraf télécharger get-pip.py (https://bootstrap.pypa.io/get-pip.py) dans le répertoire /usr/local/py installation des modules pip et requests docker exec -it fbx_telegraf wget https://bootstrap.pypa.io/get-pip.py docker exec -it fbx_telegraf python3 get-pip.py --prefix=/usr/local docker exec -it fbx_telegraf python3 -m pip install requests docker exec -it fbx_telegraf pip install unidecode EDIT du 08/septembre 2020 : installation Python sur la branche telegraf:1.5.x (i.e. tag latest) Au lieu des 7 commandes ci-dessus, on procèdera de la sorte : docker exec -it fbx_telegraf apt update docker exec -it fbx_telegraf apt upgrade docker exec -it fbx_telegraf dpkg --configure -a docker exec -it fbx_telegraf apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common docker exec -it fbx_telegraf wget https://bootstrap.pypa.io/get-pip.py docker exec -it fbx_telegraf apt-get install python3-distutils docker exec -it fbx_telegraf python3 get-pip.py --prefix=/usr/local docker exec -it fbx_telegraf python3 -m pip install requests docker exec -it fbx_telegraf pip install unidecode Il se peut que vous ayez une erreur du type : E: dpkg was interrupted, you must manually run 'dpkg --configure -a' to correct the problem Dans ce cas, .... suivre à la lettre la consigne et lancer donc la commande # dpkg --configure -a . Puis poursuivre normalement Script Python : On place le script Python fbx_telegraf_059.py dans le répertoire /usr/local/py (ce script a été mis à jour pour mes propres besoins. N’hésitez pas à le reprendre, en particulier en fonction de l'API Freebox si il vous manque des éléments) EDIT du 27/04/2021 : mise à jour du fichier python en version ed061. version basée sur l'API V8 de FreeboxOs compatibilité avec Freebox POP je conseille de repartir d'une database InfluxDB vierge cf message en page 9 pour plus de détails c'est par ici : https://github.com/bruno78310/Freebox-Revolution-Monitoring.git Modification du fichier de configuration telegraf : 1) Dans la section "Input Plugin" : ############################################################################### # INPUT PLUGINS # ############################################################################### ############################################################################### # INPUT PLUGINS FREEBOX # ############################################################################### # Read metrics from one or more commands that can output to stdout [[inputs.exec]] ## Commands array # commands = [ "python3 /usr/local/py/freebox_059.py -SPHDIWX" ] ## Timeout for each command to complete. timeout = "5s" ## Data format to consume. ## Each data format has it's own unique set of configuration options, read ## more about them here: ## https://github.com/influxdata/telegraf/blob/master/docs/DATA_FORMATS_INPUT.md # data_format = "graphite" data_format = "influx" A noter : le script python "freebox_059.py" est lancé avec un certain nombre d'options, chacune correspondant à un groupe de données récupérées. Si on n'a pas besoin de toutes ces données, selon les besoins, il est tout à fait possible de supprimer les options que l'on ne souhaite pas grapher. freebox_059.py -SPHDIWX : S : état du switch 4 ports X : liste les hosts connectés P : état des ports du switch H : system status D : status disque interne I : status des interfaces LAN W : status du Wifi 4 : status aggregation xdsl / 4g 2) modification de la base influxdb cible, section "Output Plugins" : On va envoyer nos données vers une base de données du nom de fbx_database, user fbx_databse, password fbx_database De plus, on va créer nous même cette database => skip_database_creation = true ############################################################################### # OUTPUT PLUGINS # ############################################################################### # Configuration for sending metrics to InfluxDB [[outputs.influxdb]] ## The full HTTP or UDP URL for your InfluxDB instance. ## ## Multiple URLs can be specified for a single cluster, only ONE of the ## urls will be written to each interval. # urls = ["unix:///var/run/influxdb.sock"] # urls = ["udp://127.0.0.1:8089"] urls = ["http://influxdb:8086"] ## The target database for metrics; will be created as needed. ## For UDP url endpoint database needs to be configured on server side. database = "fbx_telegraf" ## The value of this tag will be used to determine the database. If this ## tag is not set the 'database' option is used as the default. database_tag = "" ## If true, the database tag will not be added to the metric. # exclude_database_tag = false ## If true, no CREATE DATABASE queries will be sent. Set to true when using ## Telegraf with a user without permissions to create databases or when the ## database already exists. skip_database_creation = true ## Name of existing retention policy to write to. Empty string writes to ## the default retention policy. Only takes effect when using HTTP. retention_policy = "" ## Write consistency (clusters only), can be: "any", "one", "quorum", "all". ## Only takes effect when using HTTP. write_consistency = "any" ## Timeout for HTTP messages. timeout = "30s" ## HTTP Basic Auth username = "fbx_telegraf" password = "fbx_telegraf" ## HTTP User-Agent # user_agent = "telegraf" On redémarre le docker fbx_telegraf pour prise en compte Création de la database fbx_telegraf sur influxdb Se connecter en console sur le docker influxdb, puis créer la database : root@influxdb:/# influx -username admin -password admin Connected to http://localhost:8086 version 1.7.9 InfluxDB shell version: 1.7.9 > show databases name: databases name ---- _internal nas_telegraf > create database fbx_telegraf > use fbx_telegraf Using database fbx_telegraf > create user fbx_telegraf with password 'fbx_telegraf' > grant all on fbx_telegraf to fbx_telegraf > > show databases name: databases name ---- _internal nas_telegraf fbx_telegraf > show users user admin ---- ----- admin true nas_telegraf false fbx_telegraf false > On redémarre le docker influxdb pour prise en compte. Autorisation de l'application sur le Freebox. il faut autoriser l'application sur la Freebox. Pour cela se placer dans une console fbx_telegraf et aller dans le dossier /usr/local/py root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -h usage: freebox_050.py [-h] [-s] [-r] [-n app_name] [-i app_id] [-d device_name] [-f format] [-e endpoint] [-S] [-P] [-H] [-D] [-L] [-W] [-I] [-X] optional arguments: -h, --help show this help message and exit -s, --register-status Get register status -r, --register Register app with Freebox API -n app_name, --appname app_name Register with app_name -i app_id, --appid app_id Register with app_id -d device_name, --devicename device_name Register with device_name -f format, --format format Specify output format between graphite and influxdb -e endpoint, --endpoint endpoint Specify endpoint name or address -S, --status-switch Get and show switch status -P, --status-ports Get and show switch ports stats -H, --status-sys Get and show system status -D, --internal-disk-usage Get and show internal disk usage -L, --lan-config Get and show LAN config -W, --wifi-usage Get and show wifi usage -I, --lan-interfaces Get and show lan interfaces -X, --interfaces-hosts Get and show interfaces hosts On va demander d'enregistrer notre application sur la Freebox: root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -r => il faut valider sur l'ecran LCD de la Freebox. => le nom de l'application codée dans le fichier fbx_telegraf_059.py est : grafanamonitor. => controler sur la Freebox que l'application a bien été acceptée : Paramètres / Gestion des Accès / Applications on peut aussi vérifier sur la console fbx_telegraf : root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -s Status: auth already done root@fbx_telegraf:/usr/local/py# root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -r Already registered, exiting root@fbx_telegraf:/usr/local/py# Vous trouverez alors un fichiers .credentials dans le répertoire /usr/local/py . A partir de là, fbx_telegraf est en mesure de collecter les données sur la Freebox, et de les envoyer sur la base de données fbx_telegraf du docker influxdb. on peut contrôler à la main que les valeurs sont bien accessibles, par exemple : root@fbx_telegraf:/usr/local/py# python3 freebox_059.py -H | grep System freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL sys_uptime_val=2787529 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL uptime="32 jours 6 heures 18 minutes 49 secondes" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL firmware_version="4.2.5" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL board_name="fbxgw2r" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL disk_status="active" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL user_main_storage="Disque dur" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_ext_telephony=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_speakers_jack=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL wifi_type="2d4_5g" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL pretty_name="Freebox Server (r2)" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL customer_hdd_slots=0 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL name="fbxgw-r2/full" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_speakers=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL internal_hdd_size=250 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_femtocell_exp=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_internal_hdd=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=NULL,tag3=NULL has_dect=True freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Fan,tag3=NULL id="fan0_speed" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Fan,tag3=NULL name="Ventilateur 1" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Fan,tag3=NULL value=2436 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_hdd id="temp_hdd" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_hdd name="Disque dur" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_hdd value=36 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_sw id="temp_sw" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_sw name="Temperature Switch" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_sw value=48 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpum id="temp_cpum" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpum name="Temperature CPU M" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpum value=58 freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpub id="temp_cpub" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpub name="Temperature CPU B" freebox,endpoint=mafreebox.freebox.fr,tag1=System,tag2=Sensor,tag3=temp_cpub value=53 root@fbx_telegraf:/usr/local/py# Dans la console du docker influxdb, on verifie que l'on recoit bien les données de nas_telegraf et fbx_telegraf Grafana : sur grafana, definir une nouvelle source de données : Name : InfluxDB-1 Freebox (example) URL : http://@NAS:8086 (comme pour le nas_telegraf,car c'est le même docker influxdb) Access : serveur Basic auth : yes Basic auth details : user : fbx_telegraf password : fbx_telegraf Database : fbx_telegraf User : fbx_telegraf password : fbx_telegraf http method : GET On valide (SAVE & TEST) et ce doit être OK. Il ne reste plus qu'à créer le ou les Dashboard souhaités ! => Ne pas oublier de préciser l'origine des données : InfluxDB-1 Freebox Pour ma part, j'ai réalisé: un Dashboard général (trafic, CPU, status des ports du switch, températures ....) un Dashboard listant les stations actives (globales et Wifi) Resterait à faire : l'API de la Freebox est accessible ici en http. Je n'ai pas réussi par manque de connaissances à passer en https je n'ai pas regardé du tout le cas d'un accès xDSL .... le script python s'appuie sur l'API V8 de la Freebox, et est donc compatible avec les Freebox Revolution et POP. La description de cet API peut se trouver ici : https://dev.freebox.fr/sdk/os/# Enfin, tous les paramètres disponibles n'ont pas forcement été implémentés dans le script. Mais les principaux sont là. SI il y avait un besoin particulier, faites le moi savoir. Freebox-1585840825569.json Liste stations FreeBox-1585840845020.json freebox_054.py freebox_058.py