Chrome (Android)
Tap the lock icon next to the address bar. Tap Permissions → Notifications . Adjust your preference.
Chrome (Desktop)
Click the padlock icon in the address bar. Select Site settings . Find Notifications and adjust your preference.
Safari (iOS 16.4+)
Ensure the site is installed via Add to Home Screen . Open Settings App → Notifications . Find your app name and adjust your preference.
Safari (macOS)
Go to Safari → Preferences . Click the Websites tab. Select Notifications in the sidebar. Find this website and adjust your preference.
Edge (Android)
Tap the lock icon next to the address bar. Tap Permissions .
Find Notifications and adjust your preference.
Edge (Desktop)
Click the padlock icon in the address bar. Click Permissions for this site . Find Notifications and adjust your preference.
Firefox (Android)
Go to Settings → Site permissions . Tap Notifications . Find this site in the list and adjust your preference.
Firefox (Desktop)
Open Firefox Settings. Search for Notifications . Find this site in the list and adjust your preference.










![[TUTO] Monitoring réseau (Telegraf + InfluxDB 1.8 + Grafana)](https://www.nas-forum.com/forum/uploads/monthly_2019_05/tempsnip.png.270c7fadb59b88cb37cfa3b9c024fd7c.png)

![[Résolu] Comportement étrange de Jdownloader2](https://www.nas-forum.com/forum/uploads/monthly_2025_02/PJ1.jpg.87b07c3a87efebb2285424a57064dc7a.jpg)
![[TUTO] Mise à jour automatique des images et conteneurs Docker](https://www.nas-forum.com/forum/uploads/monthly_2019_08/149835638_Capturedcran2019-08-0119_40_23.png.b6086eac67984773122dd1d4dda95f55.png)


![[TUTO] Docker : Introduction](https://www.nas-forum.com/forum/uploads/monthly_2020_01/ui_docker.PNG.4b883668a428c4fb5ebb64f6240ee4e8.PNG)



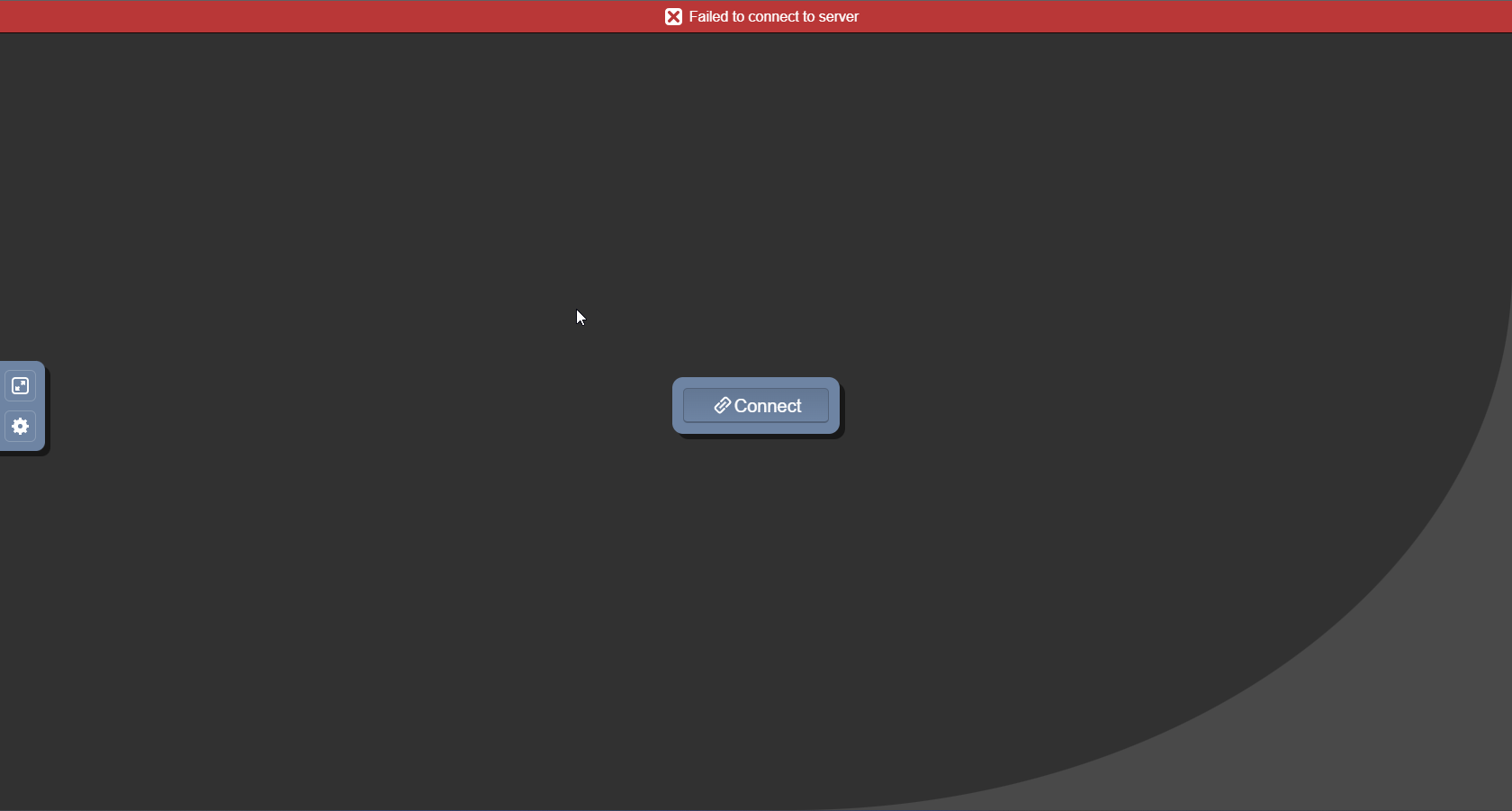
![[Résolu][RESOLU ]Synology Prowlarr, jackett sur docker The SSL connection could not be established](https://www.nas-forum.com/forum/uploads/monthly_2024_02/image.png.79597b126340ea9248ffed5e24bb57e4.png)