StéphanH
Membres
-
Inscription
-
Dernière visite
-
-
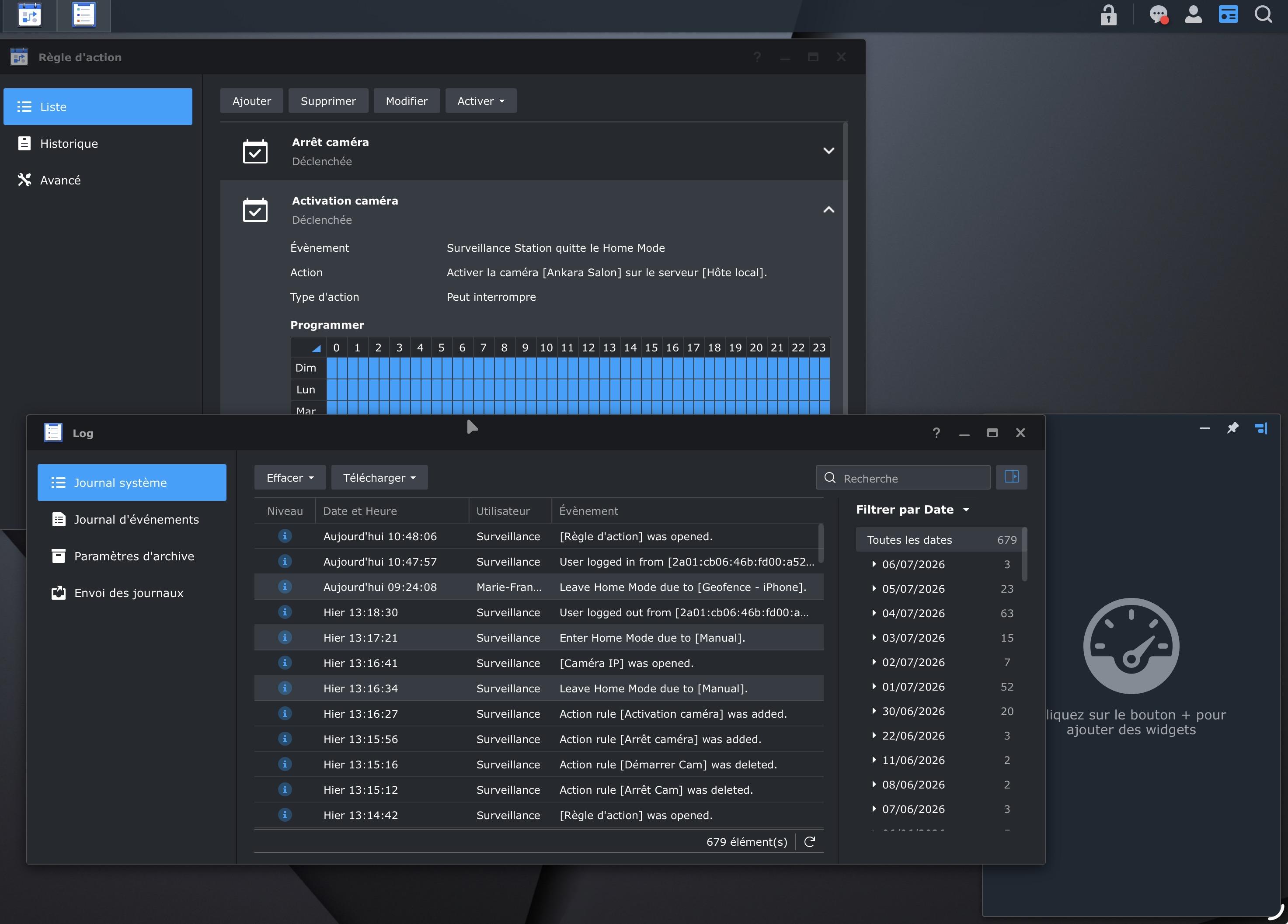
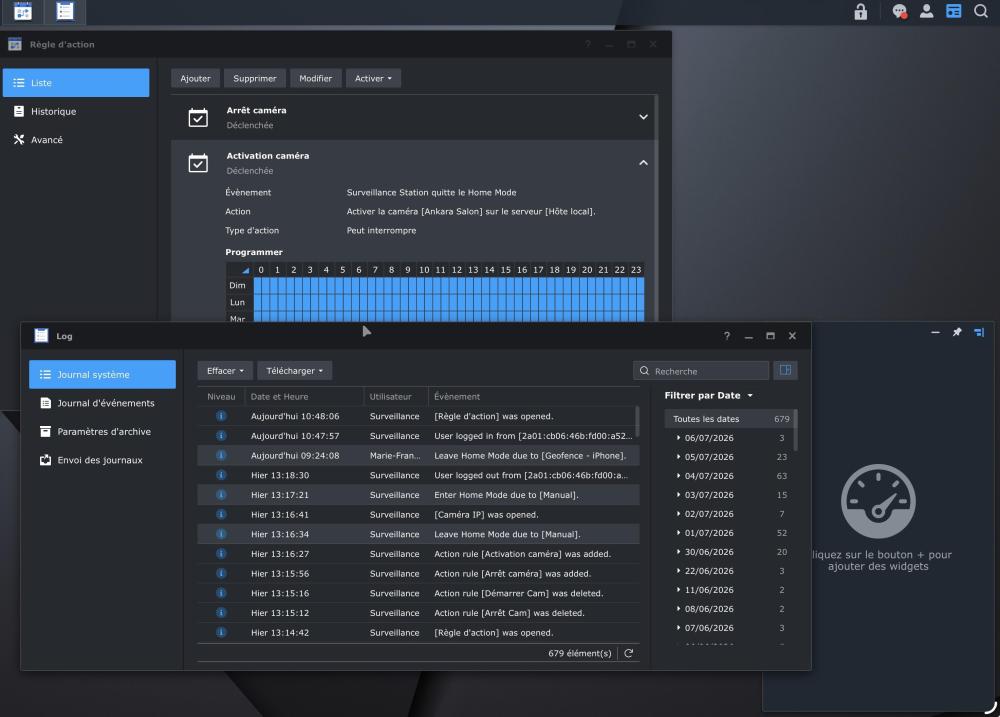
Bonjour, J’utilise les dernières versions de DSM et de Surveillance Station. Depuis 10 jours, sans action particulière de ma part, les règles d’actions sur entrée / sortie (Home Mode) ne fonctionnent plus. Ces règles visent à activer / désactiver la seule caméra de ce site. Dans les Log, on voit le Geofence fonctionner, mais les règles ne s’exécutent pas, ou bien sont affichées en « interrompu » J’ai redémarré tout le monde, désinstallé / réinstallé, DSCam, supprimé et recréé les règles, mais rien n’y fait. Je ne sais plus quoi faire … une idée ?
-
D’après Cachem, ça vient de sortir …
-
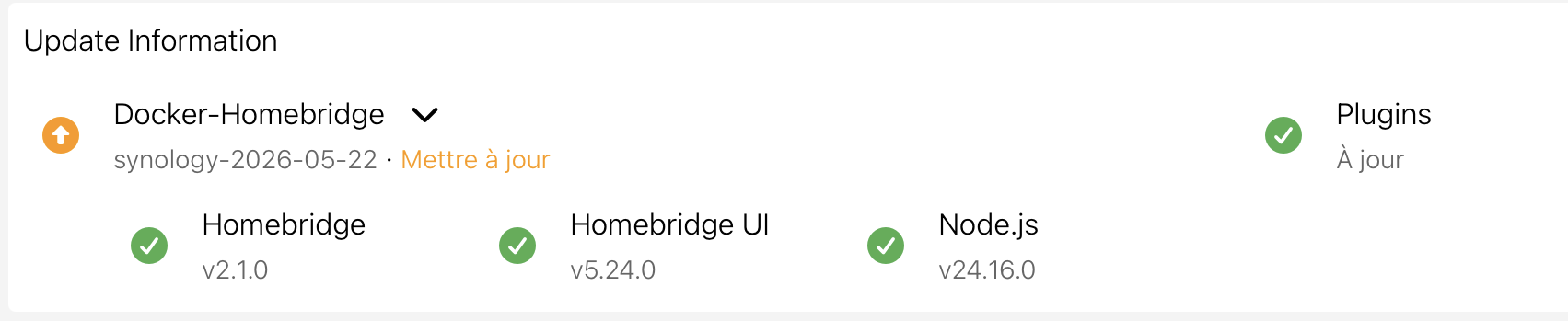
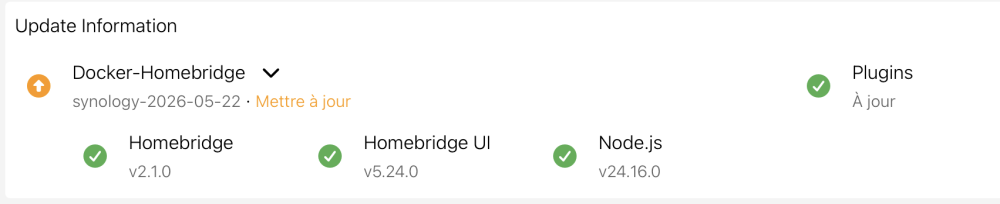
J’ai peut être été trop optimiste .. HomeBridge m’indique qu’une mise à jour est disponible : Mais au niveau de docker , pas de mise à jour proposée pour le tag synology. Je sèche …
-
J'ai franchi le pas ... J'ai donc généré un nouveau container v2 depuis l'image taguée "synology", en pointant vers le même dossier que le container d'origine, et en conservant les même paramètres réseau. J'ai lancé le container obtenu (après avoir stoppé l'ancien), et cela fonctionne. Je conserve dans le doute l'ancien container et ma sauvegarde du dossier /homebridge quelques jours ... Encore merci @Lelolo pour ton aide ...
-
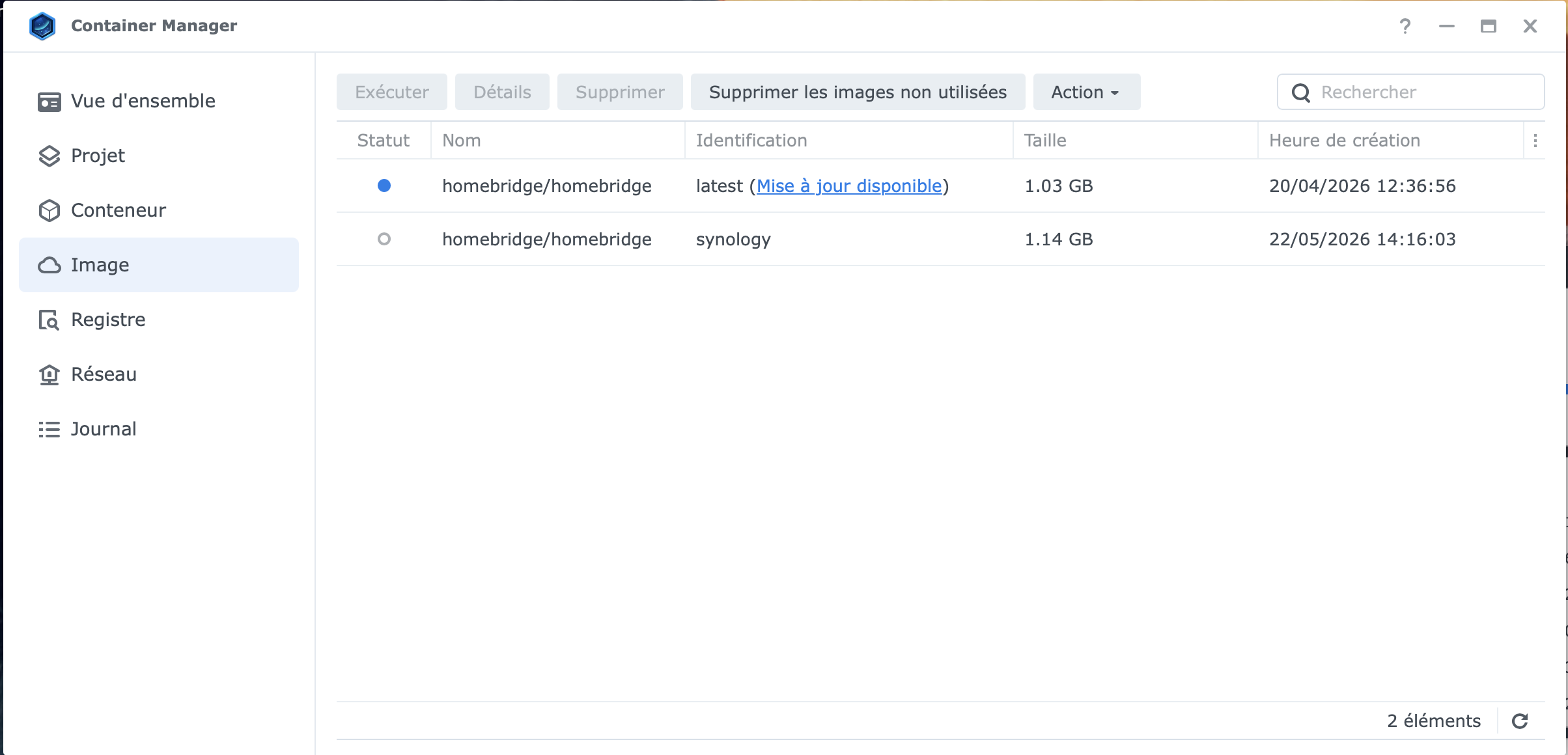
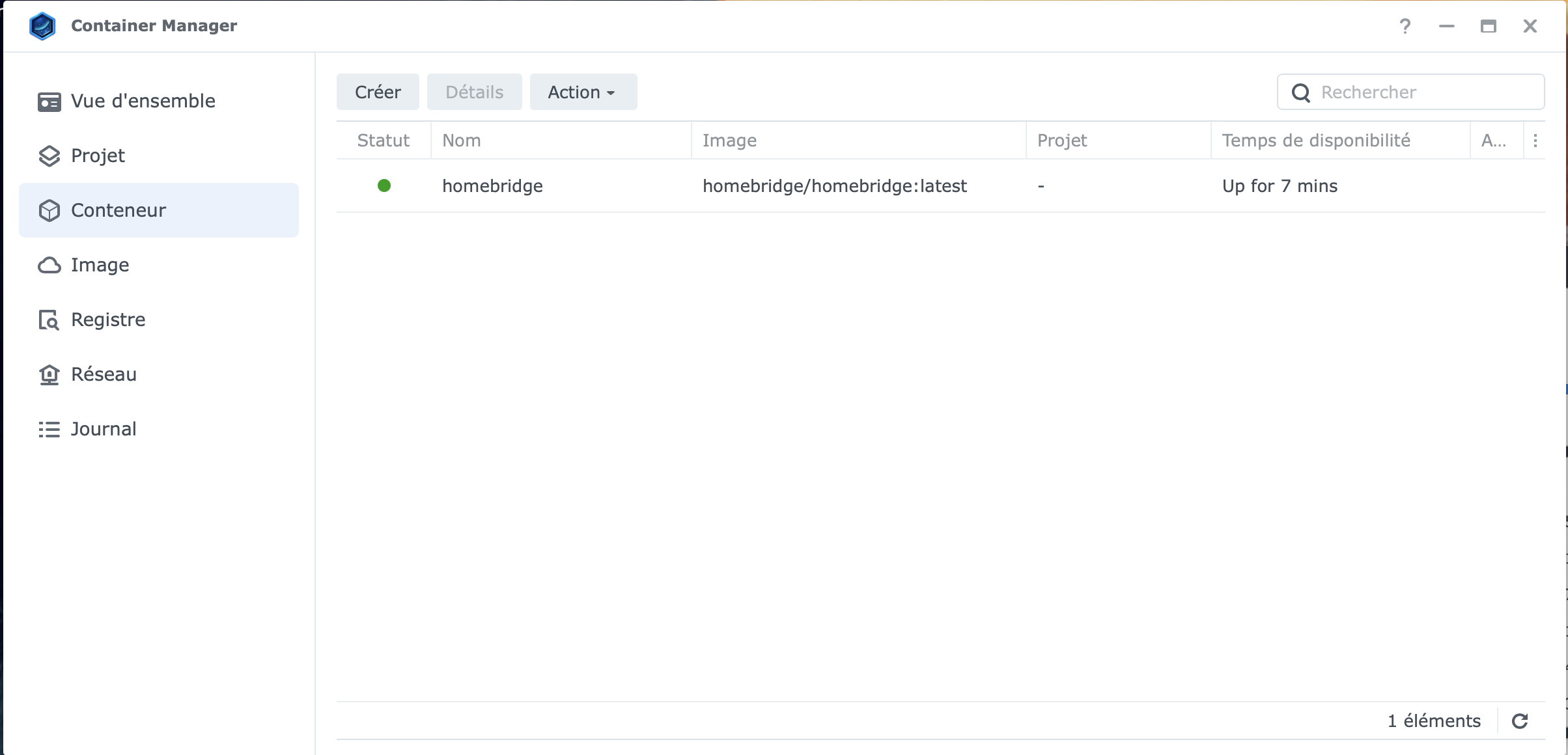
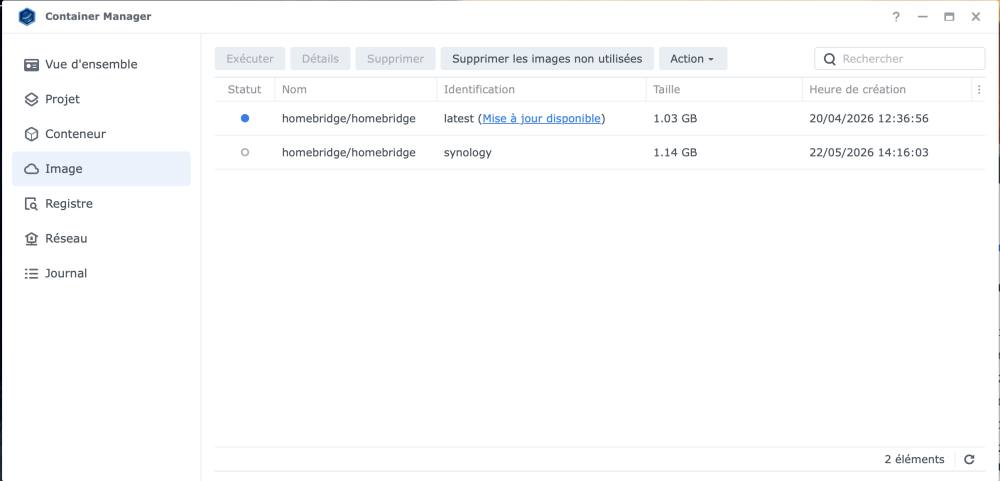
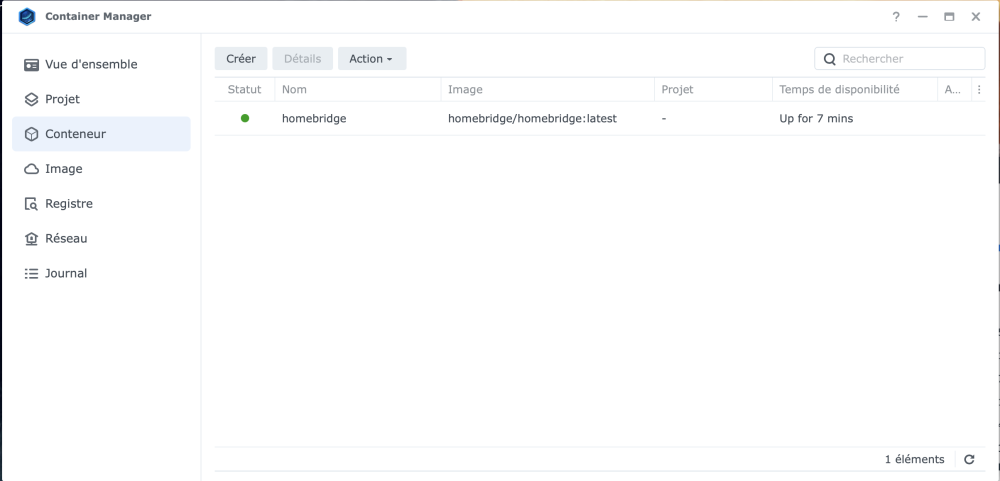
Me revoilà ... J'ai donc fait ceci : sudo docker stop homebridge sudo docker pull homebridge/homebridge:synology sudo docker start homebridge Je me retrouve avec cela : Que dois-je faire ?
-
Merci pour tout cela. Je vais m’y mettre ce week end …
-
La manipulation ci-dessous me paraît la plus simple : sudo docker stop homebridge sudo docker pull homebridge/homebridge:synology sudo docker start homebridge Toutefois, je ne comprends pas si cela se contente de mettre à jour une seule fois HomeBridge en v2 pour synology, et donc les mises à jour suivantes seront à refaire à la main, ou bien si cela fait pointer définitivement HomeBridge vers la version spécifique pour Synology.
-
J’ai si suivi ce mode d’emploi (qui date un peu) Je n’ai rien créé côté Docker Compose ..;
-
Bonjour, Sur chacun de mes NAS, je fais tourner HomeBridge en docker. Jusque là, tout allait bien. Mais HomeBridge v2 vient de sortir, et il n’est plus compatible avec les vieux Linux … ce qui est le cas de mes DS218 et DS718+ (cf GitHub) Un palliatif est disponible, via non plus la balise « latest » mais « synology » (voir ici); Il semble que cela soit trivial de pointer vers cette balise, mais je n’y connais rien … Comment faire cela sans casser la configuration ? Il semble qu’il faille passer par Docker Compose, mais là non plus je n’y connais rien Merci de vos lumières !!!
-
J’ai reçu cet avertissement ce matin …
-
Pour information, le support me confirme que l'utilisateur porteur du lien CMS entre deux instances de Surveillance Station ne doit pas être déclaré en 2FA : L'interface de connexion, bien qu'indiquant que la connexion est acceptée, ne la mémorise pas. Cela sera corrigé ultérieurement... Il convient donc de désactiver 2FA avant d'établir le lien, quitte à la réactiver ensuite. À noter que cet utilisateur peut tout à fait ne pas avoir les droits DSM.
-
À défaut de comprendre la différence entre le service HyperBackup et l’application HBVault, je comprends qu’un user HyperBackup n’a pas besoin du privilège DSM alors qu’un user Vault doit avoir ce privilège …
-
Merci pour ta patience … C’est clair ! Je me suis rendu compte fortuitement que si l’on ne coche pas la case permettant l’activation d’HSTS, on peut accéder au site en http …
-
Merci ! Du coup, à quoi sert l’indication des ports 9900 et 9901 dans cette interface ? Devrais-je mettre 443 (et rien dans le port http). ?